개 요
본 논문에서 소개하는 Cognitive SSD는 SSD에 인지력을 제공하여 에너지 효율이 있는 스토리지 내부 데이터 탐색을 수행한다. Cognitive SSD는 인지력을 주기 위해 DLG-x accelerator라고 하는 하드웨어 유닛을 SSD 내부에서 추가하여 비정형 데이터(unstructured data)에게 deep learning 과 Graph search를 수행하도록한다.
Unstructured Data
비 구조적 데이터(unstructured data)를 그대로 해석하면 "미리 정의된 데이터 모델이 없거나 미리 정의된 방식으로 구성되지 않은 정보"다. 그러나 어떤 형태의 구조를 가진 데이터일지라도 그 구조가 당면한 처리 작업에 도움이 되지 않는다면 여전히 구조화되지 않은 것으로 특정지어질 수 있다. 그래서 이메일l, 소셜 미디어, 블로그, 문서, 이미지 및 비디오의 형태로 제공되는 데이터가 비정형 데이터라고 할 수 있다.
최근에, 이런 비 구조적 데이터는 폭발적으로 증가하여 데이터 센터에서 스토리지 용량의 80%를 차지하고 있다.[1] 많은 양의 비 구조적 데이터는 데이터센터에 한번 저장되고 관리되어지면 과도한 검색/분석 요청들을 이끌어 내고 데이터 처리 장치의 처리량 및 전력소비에 심각한 문제 야기한다. 따라서 데이터 센터의 총 비용을 줄이기 위해 클라우드 서비스 인프라에서 빠르고 에너지 효율적인 데이터 검색을 지원하는 것이 중요하다.
Content Based Unstructured Data Retrieval System
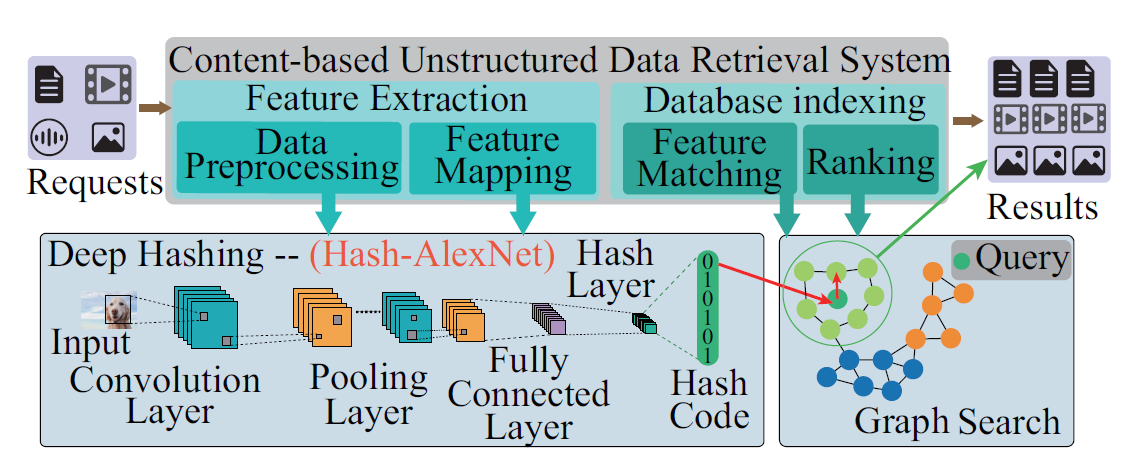
컨텐츠 기반의 비 구조적 데이터 검색 시스템은 시각적 또는 음향 적 컨텐츠를 분석하여 대규모 데이터 세트의 특정 데이터 항목을 검색하는 것을 목표로 한다. 기존의 콘텐츠 기반 검색 절차는 feature Extraction과 Database Indexing 두 가지 주요 단계로 구성되어 있다. feature Extraction은 query 데이터에 대한 feature vector를 생성하고, Database Indexing은 해당 feature vector가있는 스토리지의 유사한 데이터 구조를 검색한다. 그러나 기존 시스템은 나쁜 검색의 정확도를 보여준다.
그래서 본 논문에서 검색 절차에서 두가지 절차에 대해서 Deep Hashing과 Graph Search를 제안한다. 먼저 Deep Hashing에는 Convolution Layer, Pooling Layer, Fully Connected Layer, Hash Layer 네가지의 네트워크 계층이 있다. (1)Convolution Layer는 입력 데이터에서 다차원 필터를 이동시키며 convolution 연산을 수행하여 입력에서 특징을 추출한다.(2) Pooling Layer는 스케일 및 기타 불변 유형의 입력 채널을 다운 샘플링하고, (3) Fully Connected Layer는 피쳐와 학습 된 가중치 사이의 선형 연산을 수행하여 입력 데이터의 분류 또는 특성을 예측한다. (4) 마지막으로, Hash Layer는 특성을 해시 코드로 변환한다.
그다음 Graph Search는 정확하고 빠른 데이터 검색 결과를 얻을 수 있다. 그래프의 각 vertex는 인스턴스를 나타내며, edge는 entity 간의 유사성을 나타낸다. query 기반 이웃 개념은이 시스템에서 잘 적용될 수 있다. 가장 가까운 이웃 탐색은 그래프에서 이웃들의 이웃을 반복적으로 검사하여 이웃을 찾을 수 있기 때문이다. 이러한 방식으로, 검색 대기 시간을 줄여 불필요한 데이터 검사를 피할 수 있다. 요약하자면 deep hashing 이후의 Graph search 를 하는 방식은 brute-force search 또는 해시 알고리즘을 사용하는 기존 솔루션에 비해 낮은 대기 시간 및 고정밀 검색 성능을 제공 할 수 있다.
소프트웨어 하드웨어의 문제점
소프트웨어 관점에서, 현재 리눅스 커널의 I/O 스택은 File System/VFS, Block I/O Layer, SCSI Layer, Device Driver 로 구성 되어 있다.(그림 2) 커널 I/O 스택은 60.8us의 latency를 가지는데 기존에 스토리지로 사용된 하드디스크는 2~5ms의 latency를 가졌다. 그러나 SSD와 같은 고성능 스토리지는 50~75us의 latency를 가진다. 이런 고성능 스토리지는 사용하게 되면서 성능 병목 현상이 스토리지에서 커널 I/O 스택으로 옮겨졌다.

하드웨어 관점에서, 대규모 데이터 이동은 일반적인 메모리 계층에서 에너지 및 대기 시간 오버 헤드를 유발한다. CPU나 GPU에서 연산을 하기 위해서 스토리지의 데이터가 저속 I/O 인터페이스, 메모리 및 캐시를 통과해야 하기 때문에 데이터의 규모가 커지면 문제는 심각 해진다.
Cognitive SSD System
Cognitive SSD는 개발자가 데이터 검색 솔루션을 사용자 정의하고 구현할 수 있도록 DLG 프레임 워크의 주요 구성 요소를 지원하도록 설계되었다. 이 근거리 데이터 검색 시스템은 DLG 라이브러리 및 Cognitive SSD 하드웨어라는 두 가지 주요 구성 요소로 구성된다. 먼저, Cognitive SSD 하드웨어는 PCIe 인터페이스를 통해 호스트 서버에 연결된다. 그리고 Cognitive SSD 시스템의 인터페이스로서 NVMe 프로토콜의 I/O 명령 세트에서 Vendor Specific Commands를 활용하여 DLG 라이브러리를 구축한다. DLG 라이브러리에는 Config Library와 User Library가 포함되어 있다. 관리자는 Config Library를 사용하여 다양한 심층 학습 모델을 선택하고 배포 할 수 있다. 그래서 Cognitive SSD는 애플리케이션 요구에 신속하게 부합한다. Cognitive ssd 하드웨어는 기본 SSD 하드웨어에 DLG-x 가속기를 추가하고 이에 따라 펌웨어가 수정되었다.

Config Library는 널리 사용되는 심층 학습 프레임 워크 (예 : Caffe, Pytorch)와 호환되는 DLG-x 컴파일러를 제공한다. 그리고 관리자는 새로운 심층 학습 모델을 교육하고 해당 DLG-x 지침을 오프라인으로 생성 할 수 있다. User Library에는 Task Plane과 Data Plane이 있다. DLG-x 가속기의 확장성을 개선해 주는 Task Plane은 DLG-x 가속기는 Deep Hashing 및 Graph Search을 지원한다. Data Plane은 사용자가 호스트 서버와 Cognitive SSD 간의 데이터 전송을 제어 할 수 있도록 SSD_read 및 SSD_write API를 제공한다. 이 두 명령은 Flash Translation Layer를 우회하는 실제 주소에서 직접 접근한다.

기존 하드웨어 가속기와 달리 DLG-x 가속기는 NAND 플래시에서 작업 세트 데이터의 대부분을 직접 얻을 수 있도록 설계되었다. DLG-x 가속기에는 두 개의 활성 버퍼 (InOut 버퍼)와 weight buffer가 있다. weight buffer는 신경 처리 엔진 (NPE)과 플래시 사이의 브리지 버퍼 역할을하고, 각 신경 네트워크 계층의 중간 결과는 활성화 버퍼에 일시적으로 저장된다. NPE는 고정 소수점 컨볼 루션, 풀링 및 활성화 함수 작업을 수행 할 수있는 PE (Processing Engine) 세트로 구성된다. Graph Search Engine은 NPE에 의해 생성 된 해시 코드로 그래프 검색을 담당한다.NPE 및 GSE는 플래시 메모리에서 instruction을 가져 오는 제어 장치에 의해 관리된다.
Data Layout
NAND 플래시의 I/O 동작을 고려할 때, 높은 내부 플래시 대역폭을 활용하기 위해 Neural Network의 데이터 레이아웃을 재구성한다. 데이터 레이아웃은 read page cache 명령어를 사용하여 플래시 대역폭을 최대한 활용한다. read page cache 명령어는 블록 내의 다음 페이지를 데이터 레지스터에 연속적으로 로드 할 수있다. 이전 페이지는 Cache Register로부터 DLG-x의 버퍼 또는 캐시 영역으로 읽게 된다. 따라서 제공된 read page cache 명령어를 사용하는 NAND 플래시 아키텍처를 기반으로 컨볼 루션 커널을 분할하여 플래시 장치에 저장하도록 한다. 즉, 각 컨볼 루션 커널은 서브 블록들을 만들어 플래시 채널에 interleaving된다. 그렇게 낸드 플래시의 병렬 처리를 극대화할 수 있다.

DLG-x가 하나의 Vertex의 인접 영역에 액세스 할 때마다, 플래시에서 하나의 전체 페이지를 읽어야하는데, 이는 지역성이 잘 유지되지 않으면 낮은 대역폭 사용률을 유발할 수 있다. 접근 된 Vertex의 이웃들이 공간 지역성으로 인해 곧 사용될 것이라는 것을 추론 할 수있다. 따라서 그림 6에 표시된 것처럼 V0 및 모든 이웃 (V3; V2;)은 페이지의 시작 부분에서 연속적으로 정렬되고 저장된다. 이것이 플래시 액세스를 줄이는 것에 도움을 준다.


